




Chronos: An RL driving policy that crossed the sim-to-real gap
2024 / Student project, TU Dortmund / CRS + ROS + MATLAB + Python + Docker + Git + Reinforcement Learning

TLDR
Student project at TU Dortmund (Lehrstuhl RST, supervised by Prof. Frank Hoffmann). Several teams worked the same brief in parallel, each taking its own approach: drive a ~1/8-scale Ackermann car around a taped track using a policy trained entirely in simulation. The policy I worked on saw lateral and heading error plus three lookahead curvature samples, trained with a mix of offline and online RL in the lab's open-source CRS simulator (rendered in RViz), with starting positions randomised on every episode to stop it overfitting to one approach. Tooling was MATLAB and Python, with ROS handling the car–host link and Docker + Git keeping the setup identical between sim and the car. Both halves were hard: learning the track, and behaving the same way on real hardware. Watching the trained agent complete full laps on the physical track — on cheap hardware — was the payoff.
Video of the trained policy driving the real car: public footage on YouTube.
What the project was
A ~1/8-scale Ackermann car, a taped track, and the question of how to make it drive the line. Classical path-following controllers work fine for this, and that was part of the point — the project wasn't motivated by a control problem we couldn't solve another way. The point was to try reinforcement learning end-to-end: pick a controller architecture that's normally easy, replace it with a learned policy, and see what breaks when you take that policy out of simulation and onto real hardware.
Training the policy
Training came in two phases. First, offline: we collected rollouts from a PID controller driving the track in simulation and trained the policy to imitate them. That gave us a starting policy that could roughly follow the line, but only roughly. Second, online: the policy drove in the CRS simulator (rendered in RViz) and updated from the reward signal each episode.
The state the policy saw was small on purpose: lateral error, heading error, and three lookahead samples of the track ahead, each as an arc-length and curvature pair. Eight numbers in total — but the three lookahead samples were doing most of the work. Without them the policy is reactive, only ever correcting what's already gone wrong. With them, it can act on what's coming: start turning into a corner before the heading error has built up, ease off before a straight begins. The difference is between chasing the track and reading it.
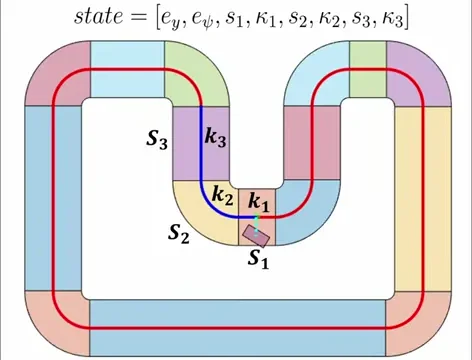
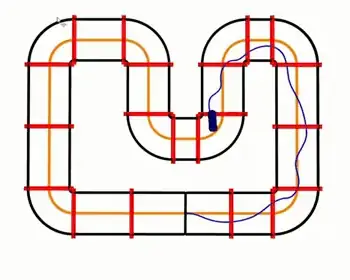
The thing that nearly broke the project was a generalisation problem. With non-randomised starts the policy learned the first corner of the track in detail and then had no idea what to do with the second. Randomising the starting position on every episode forced the policy to see every part of the track from every approach. In the simulator that looked like a tangle of trajectories saturating the whole track — and behaviourally it was the difference between a policy that knew one corner and a policy that knew the track.
Crossing the sim-to-real gap
The policy oscillated — not catastrophically, but visibly hunting, both on the real car and in simulation. The sim-to-real gap made the hunting worse on hardware, but didn't create it. The policy was producing a control signal that wasn't smooth, and we never fully isolated the cause: reward shape (no penalty on action deltas), action-space resolution, network capacity, and the lookahead samples not giving a long enough horizon to act gently were all candidates.
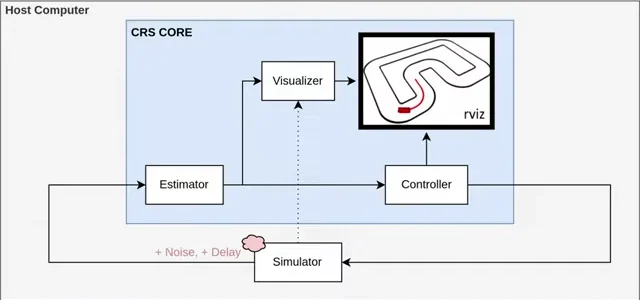
The engineering work narrowed the gap on both sides. It meant making the simulator behave more like the car (action-space limits matching what the motor controllers could actually deliver, observation rates matching what the real sensors produced at the real sample rate) and making the deploy reproducible enough that the policy ran the same way every time it was loaded. CRS handled most of this: it was set up so the same policy code, the same observation interfaces, and the same action interfaces could be pointed at either the simulator or the real car with no source changes. Docker and Git kept the runtime identical on top of that, and ROS handled the actual messages on both sides — the policy didn't know whether it was talking to simulated wheels or real ones.
The result
By the end of the project, the policy could drive the full track on the real car, lap after lap. The randomised-starts training carried generalisation across the whole track without retraining, and the bicycle + Pacejka dynamics in the simulator were close enough to reality that the policy stayed on the line once it was deployed.

The honest qualifier is the one already flagged: the policy was never smooth. Even in simulation it visibly hunted, and on hardware that hunting got slightly worse. We didn't fully diagnose the cause. The most likely fix would have been a different reward shape (penalising action deltas, not just position error) or action-side filtering, but we ran out of project before we could test either.
Concepts worth taking away
Three things from this project that have stuck with me:
- The state design matters more than the algorithm. The eight numbers the policy saw (and especially the three lookahead samples) did more for the final behaviour than any RL hyperparameter we tuned. The policy could only ever be as smart as what we let it see.
- Randomising starts is the cheapest generalisation trick in RL. It costs nothing at training time, fixes a class of failure that's otherwise hard to diagnose, and the visualisation of the resulting trajectory tangle is its own debugging tool.
- Not every gap is a sim-to-real gap. Our policy oscillated on the real car, and the obvious instinct was to blame the sim — but it oscillated in sim too. CRS, Docker, Git, and ROS gave us a clean interchange between the two sides, which is exactly what you want for diagnosing where a problem actually lives. The smoothness problem was in the policy itself, not the gap; we ran out of project before fixing it.
Technologies and patterns
Built on the CRS framework, the open-source RC-car testbed maintained by ETH Zürich's Institute for Dynamic Systems and Control. Around CRS: ROS for the car–host link, Docker and Git for reproducible runs, MATLAB and Python for the policy, RViz for visualisation.